
Website Concept
Before talking about how to create and publish a website, I think it's warranted to first explain what is a website in the first place?
From the browser's point of view
When you type judi.systems into the browser's address bar, many things happen,
but we'll focus on a few critical steps that are relevant to us:
(1) Domain -> IP translation
The internet's connection protocols do not work with domain names, they work with IP addresses, so before connecting to a website, the browser needs to know the IP address.
The DNS (Domain Name System) protocol defines how domain names map to IP addresses, and how a client (such as your browser) can query the network to read the domain -> IP mapping.
When you buy a domain name from a provider such SquareSpace or NameCheap, you can configure DNS entries in order to map domain names to IP addresses.
This is kind of a simplification and there are more nuanced details that we do not to get into for the time being.
For the domain judi.systems, I have a DNS record of type A that map it to 207.148.96.165.
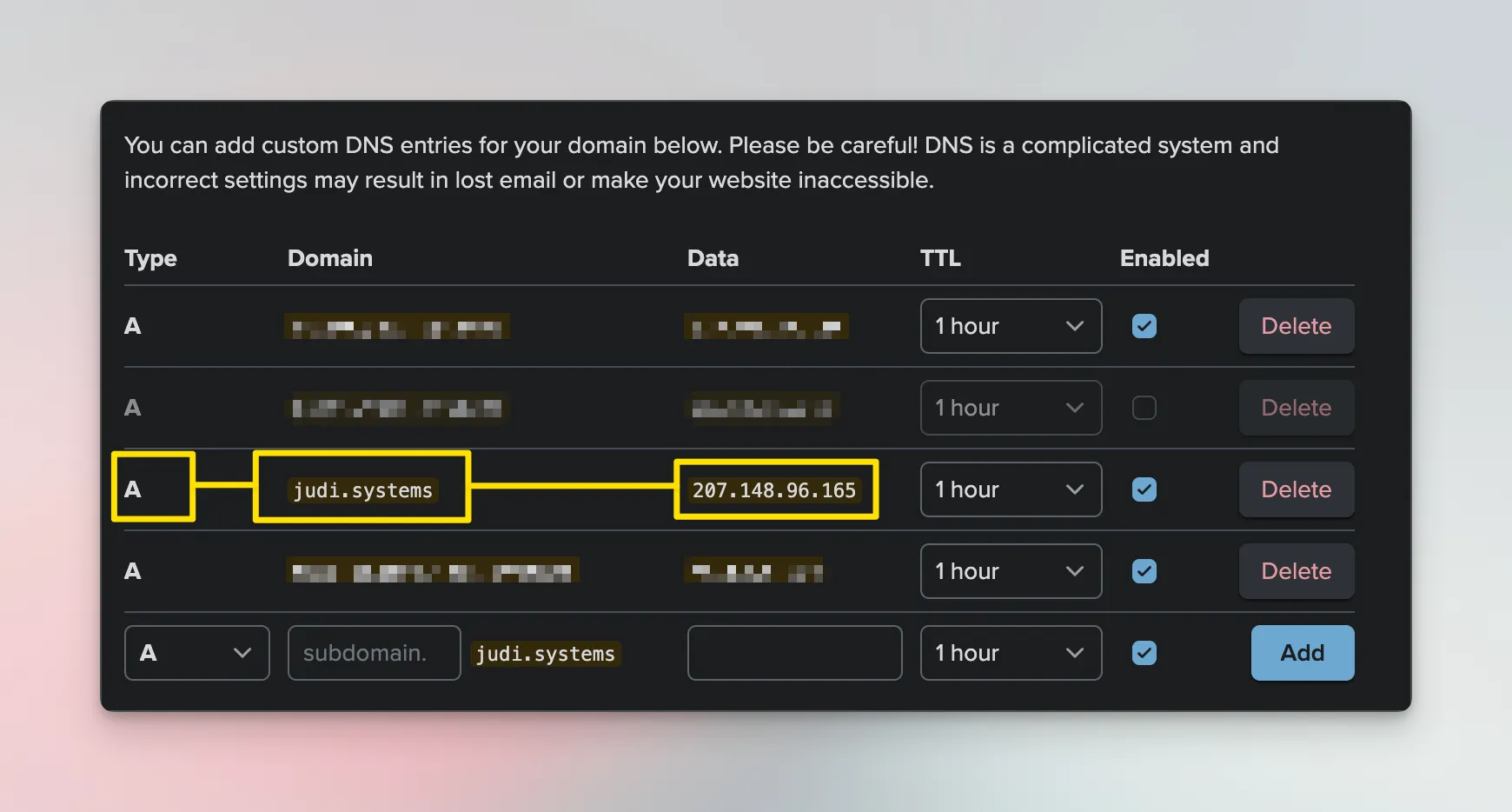
This is not sensitive data, by the way; it's publicly available information.
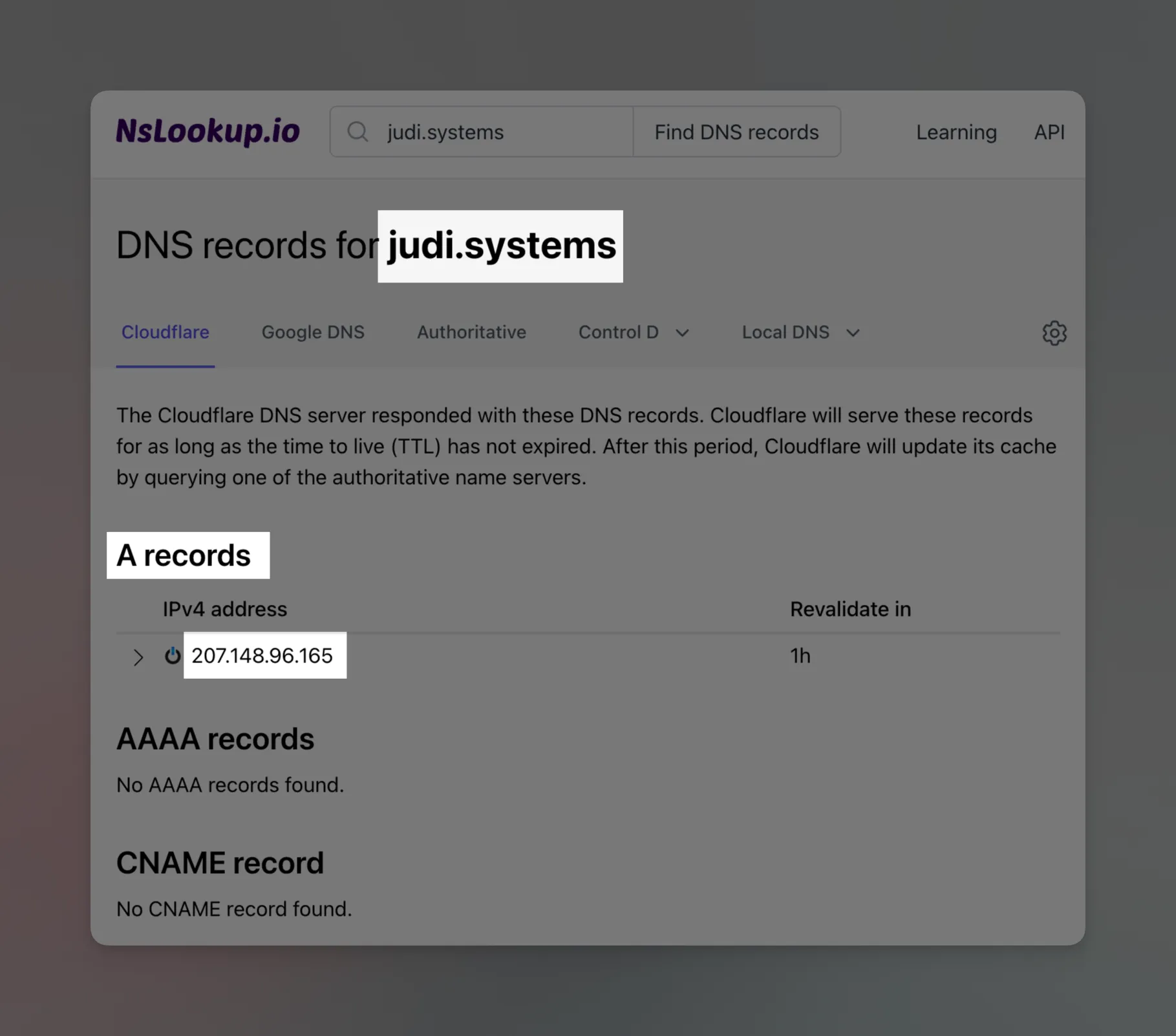
You can issue (via your terminal) the command nslookup judi.systems to find it
out, and there are also websites that do it for you; for example: https://www.nslookup.io/domains/judi.systems/dns-records/
(2) TCP connection and HTTP(S) request/response
The browser will connect to the IP address, using the TCP protocol, on either
port 80 (if using http://) or port 433 (if using https://).
It will create an HTTP "request" that asks for the given domain name and the url
For example, when loading https://judi.systems/:
- TCP:
- Address:
207.148.96.165:433
- Address:
- HTTP:
- Domain:
judi.systems - URL:
/ - Method:
GET
- Domain:
The server will inspect the request, and decide how to respond to it. The client (the browser) will receive the response and decide how to handle it.
In the most basic scenario, when you request a webpage, the server will respond with the html content, and the browser will render it on the screen.
From Sprouts' point of view
For sprouts, at least in the current version, a website is a directory from which to serve content.
In the future, when we add dynamic features, it will also include a database from which to read and write data for the dynamic features.
When receiving a request, it will check the domain, and if it knows about it, it will look for its directory, and if it finds it, it will use the url path to look for a file path within that directory.
If the file is a template, it will render the template (caching the result for future requests) and send the result as the response, otherwise it will send the file as-is.
If the request ends in / indicating it's a directory, it will look for index.html
or index.tmpl in that directory.
sprouts has a root directory where it expects to find websites. If you
installed sprouts normally using the instructions provided in the previous page,
sprouts will look for websites in: /opt/sprouts/sites/<domain>
In the case of judi.systems, it will look for /opt/sprouts/sites/judi.systems
Since the url is / it will look for /index.html or /index.tmpl inside that
directory and use it to build the response.
From Gardener's point of view
For Gardener, a website is not just a directory from which content is served; it's also a thing that can be published to a sprouts instance running on a linux server.
Gardener is also a bit more flexible, in that it does not require all sites to be in the same "root" directory. A site directory can be placed anywhere, and the name need not match the site's domain name.
You can create two sites from the same directory, and treat one of them as the staging website for example, by assigning it a different domain.
You can also setup multiple servers and put different websites on each of them using the same local directory.
Note that DNS record must be setup properly in advance.